Last month, my 6th grader studied plant and animal cells and their parts in science. We needed help, and I came up with a few worksheets. Our Plant and Animal Cell Worksheets will help your student recognize and remember the functions of the animal cell organelles and plant cell organelles.
Our free printable worksheets for plant and animal cells include the perfect visuals for your animal cell project in Grade 6. If you need animal cell poster ideas, your student can create a stunning posterboard using the various graphics and information included.
This set was originally created by This Sweet Life exclusively for Homeschool Encouragement. We re-branded HomeschoolEncouragement.com and moved over to EncouragingMomsAtHome.com a few years ago.
I decided this week it was time to completely update and revise the plant and animal cell worksheets to fix errors, bring the design up to date and add several new pages like the brand new plant and animal cell crossword puzzle! We’ve included everything from the old set and more. We think you will love the changes! You will find the download link at the end of this post.

How to use the Plant and Animal Cell Worksheets
By clicking the link below you will be able to get your own personal set of the plant and animal cell worksheets. Each PDF file is for a single teacher. Once you have the worksheets, print off one set per student. A color printer is preferred as it really helps the student differentiate between the different parts of the cell. You can use these in the classroom and in your homeschool.
Learning with a Vocabulary Flipbook
The first thing we did was use the flipbook to record the function of each of the organelles. We are using Pandia Press’s R.E.A.L. Science Odyssey: Biology Level 2. Therefore, our definitions match her text; however, you can use the definitions in your own textbook.
The beauty of this flipbook is the fact that she could quiz herself on the definitions. She would look at the name of the organelle, say the definition from memory, then lift the flap to check herself.
Vocabulary words included in our plant and animal cell worksheets cover all the parts of plant and animal cells and more: nucleus, cell wall, vacuole, chloroplast, lysosome, endoplasmic reticulum, cytoplasm, ribosomes, Golgi bodies, mitochondrion, proteins, mitochondria, plasma membrane, Golgi apparatus, eukaryotic cells, chlorophyll, nucleolus, nuclear membrane, lipids, vesicles, cytoskeleton, and even the stages of mitosis.

Learning about Plant and Animal Cells with Flashcards
After writing out all of her definitions and reviewing them with me, she used the vocabulary cards to play a matching game. She worked until she could match the organelles and their functions. Kids love playing several different flashcard games to take this even further.

Animal Cell Poster Ideas for Your Animal Cell Project
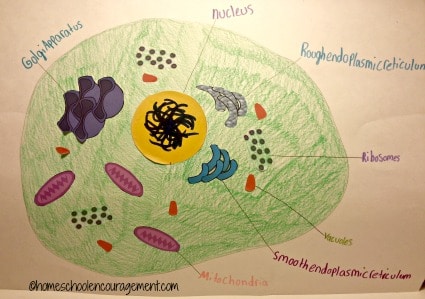
Once I was sure she had the organelles and their functions down, she created an animal cell poster. I had her cut out the organelles and lay them out on the poster board to make sure they all fit the way she wanted them. Then, she penciled in the cell membrane. She picked the organelles back up. She traced the cell membrane and colored in the cytoplasm before gluing the organelles down. I had her label as many organelles as she could from memory. She got them all!
Plant and Animal Cell Venn Diagram
Compare the two different types of cells using our handy Venn diagram. This is a great way to learn and review the differences. Don’t forget to pull out the microscope slides and compare the two different types of cells up close.
Blank Cell Diagram Pages
Quiz your students about the various parts of each cell type using the blank cell diagrams included in the plant and animal cell worksheet set. We actually have included a fully labeled set as well so you don’t have to find a different model for your students to study. There is a blank animal cell diagram and a blank plant cell diagram in both black and white and color options.
Plant and Animal Cell Word Search
Help students get more familiar with the vocabulary and spelling of organelles using this fun word search. We’ve revised this from the original version and you are going to love the changes!
Plant and Animal Cell Crossword Puzzle
Students can review all of the different definitions using this engaging crossword puzzle.
Plant and Animal Cell Coloring Pages
Give your artistic students a beautiful way to review the content of your plant and animal cell unit. Offer coloring pencils, watercolors, markers, or gorgeous oil pastels for this coloring page.
Fill In The Blank Review Pages
When your students are ready, use our fill-in-the-blank animal and plant cells worksheet questions to test them on their newfound knowledge about plant and animal cells!
Organelle Printouts
These are so handy for creating your animal cell project or plant cell project! Simply print these out, laminate them, and use them to create stunning cells and definitions for your animal cell poster.
How to Make an Animal Cell Project or Plant Cell Project.
Before you begin, choose a specific type of cell to feature in your display. Will you choose animal cells or plant cells?
Create a Cell Poster
Start by using our animal cell poster ideas (or plant cell) to create a gorgeous posterboard for display. This is the cornerstone of every great science project! You’ll want to include vocabulary and parts of the cell on your poster board. Pictures and diagrams such as those in our plant and animal cell worksheets will work great!
Add More to Your Plant or Animal Cell Project Display
Once you have a great poster design, consider what else you might add to the display. You could have a microscope with slides for comparison, printed photographs of the various cell types in frames, and a 3D Cell Model.
Building a 3D Cell Model for your Plant or Animal Cell Project
Once you have the posterboard for your cell project ready, you might want to build a 3D model for display. Your student can use clay, candies, sprinkles, cake, cardboard, beads, buttons, pipe cleaners, styrofoam balls, jelly beans, yarn, raisins, gelatin, glue, and even play dough to build the 3D Cell Model.


Hi! Thank you for sharing your cells!! Great ideas!
What a wonderful printable collection! Just what I was looking for . Thank you so much for sharing!
I love this… I teach a SDC Science class. Love the visuals and colors 🙂
This is perfect for our lesson! Thanks for all of your hard work in creating this!!
wow this is great thank you !
Hello, Thank you for taking the time out to help Mom’slike myself be able to help my daughter learn a more easy effective way. It was a great learning tool and she really understood the difference between the two cells. Thank you for your creativeness, time, and dedication. May God Bless you
Thank you very much!! This resource is absolutely fabulous! Thank you!
Lisa C
Thank you so much ! So easy to print, high quality. I really appreciate it
Is there answer shhets for the word seach? My students are going crazy with it!
Yes there needs to be answer sheets for these, thank you.
Thank you for this resource! My 3rd grade team and I will have a blast using it!
Hello, this is awesome! Do you happen to have a B&W version of the printables?
I love you I love you I love you I love you! Seriously, you just saved me. I am just now day 1 starting to homeschool my daughter. (we are on day 1 eek!!!) There is supposed to be a teacher coming weekly but since that hasn’t started and I have no clue when it will actually start, I decided to jump in based on what she was learning at school. I have spent the last hour trying to come up with a ‘packet’ so we can work on cells. I stumbled upon your site and I can’t thank you enough. I feel like a have a starting off point now and I don’t feel so lost. Thank you again!!
That’s wonderful! You can do this mom 🙂
This is great – thank you so much for sharing!!
You are very welcome.
This is exactly what I was looking for (and more!) to use along with our Apologia anatomy unit on cells. This is fun and colorful and so well done. Thank you SO much for sharing this!!!
Thanks for the cell packet ! its very thorough and will be easy for my students to complete. Just what I needed!!! Thanks for sharing!!! : )
Thank you. I will do this with my little girl.
Thank you so much for this free resource! I am tutoring a student who cannot come to school, and this is very helpful.
So good for my little girl, thanks
Just what I needed! Thank you so much for sharing
hey Tara I was wondering if this unit is still available? I am not able to download it so I wasn’t sure. thanks!
Yes, the download is still available and working. Send me an email and I’ll send you the file 🙂
thanks! the email is desiringabc@gmail,com
Thank. You. So. Much. I paid $4 for a TPT craftable resource, and this is far superior.
Thank you so much for sharing this worksheet!
Am I allowed to use this material for my classroom?
Yep!
This is Awesome! Just what I was looking for.
This such a wonderful package, well thought out and put together, I can’t wait to use it, Biology is my all time favorite subject.
Thank you for making it free to use, we have a somewhat small budget.
Thank you so much!!! I have an 11 year old daughter that is Dyslexic and I teach her with visual learning. These are great pages you have shared!!!!
I’ve just landed on your page for the first time and I love you already! My little boy is gifted, driven to learn and very active. At seven years of age it is tricky to find materials that present the level of information he needs (hungers for) in a way that is accessible to him (supersizing and incorporating physical activity and novelty is really important). I will certainly be hanging around here for a while. Thank-you so much for generously sharing your cells pack.
We were unable to find “cell wall” and smooth ER on the word search. Is there a key to go with all of this?
THANK YOU THANK YOU!!!! This is AWESOME.
Waow…this is amazing…
thank you!
Hi! Thank you for publishing this learning pack such a great help for my daughter to learn about cells.
Thank you so much for offering these pages. They were exactly what I was looking for. I have them printed off, and I am excited to do these with my daughters this week!
This packet is wonderful! Thank you for sharing!
Thank you, it’s really usefull
Thank you so much for this free print out. The kids loved it and made it fun for them to learn.
Wow, that’s a wonderful collection. Exactly what I want. Thank you so much for sharing it.
Thank you very much for sharing this! We do Classical Conversations and Cycle 1 has 2 weeks on animal and plant cell parts. My boys will really enjoy this!
Thank you. This was perfect!
Que buen material, gracias por compartirlos!!!
Thank you so much for this! Wish I had stumbled upon it first when I started searching 30 minutes ago, lol.
Very helpful. Thank you for this
thanks for the help
Thank you so much, this is perfect for our plant/animal presentation project
Thank Your for Sharing !!
Thank you these are great! Very fun and colorful.
Thank you so much for sharing. This is really going to help my 5th graders!
This is AMAZING!!! I appreciate this so much – thank you thank you!!
Thank you! These are a great addition to our unit!
it looks very nice. thank you <3
This is great!
I can’t figure out how to print this. Can you help me?
You will need to have pop-ups enabled and click the link at the end of the post.